Ladevorgang...

Der Physiker Metin Tolan hat einmal geschrieben, dass eine Fußballmannschaft Tore nach fast derselben Statistik schießt, nach der ein radioaktiver Atomkern zerfällt. Was auf den ersten Blick absurd klingt, beschreibt eine fundamentale Wahrheit: Fußball folgt statistischen Gesetzmäßigkeiten, auch wenn das einzelne Spiel vom Zufall dominiert zu sein scheint. Diese Erkenntnis bildet das Fundament aller KI-gestützten Vorhersagen. Zahlen und Fakten bilden das Fundament für eine treffsichere AI Fussball Vorhersage.
Wer sich ernsthaft mit AI-Fußballprognosen beschäftigen will, kommt um ein Grundverständnis der Statistik nicht herum. Das bedeutet nicht, dass man Formeln auswendig lernen oder komplizierte Berechnungen durchführen muss. Es bedeutet, die Logik zu verstehen, nach der Algorithmen arbeiten, und die Grenzen dieser Logik zu kennen. Nur wer versteht, was statistische Modelle können und was nicht, kann ihre Outputs sinnvoll interpretieren.
Dieser Artikel erklärt die statistischen Grundlagen, auf denen KI-Vorhersagen im Fußball aufbauen. Er zeigt, welche Konzepte zentral sind, welche Methoden verwendet werden und wo die häufigsten Fallstricke lauern. Am Ende steht kein Expertenwissen in Mathematik, aber ein solides Verständnis dafür, wie datenbasierte Prognosen funktionieren und warum sie manchmal funktionieren und manchmal nicht.
Die Rolle der Statistik im modernen Fußball
Fußball war lange Zeit eine der letzten Bastionen gegen die Vermessung der Welt. Während in amerikanischen Sportarten wie Baseball oder Basketball seit Jahrzehnten akribisch Daten gesammelt und ausgewertet wurden, regierte im Fußball das Bauchgefühl. Trainer verließen sich auf ihre Erfahrung, Scouts auf ihr Auge, und Fans auf ihre Intuition. Statistiken galten als Spielerei für Leute, die den Sport nicht wirklich verstanden.
Diese Zeiten sind vorbei. Der Wandel begann schleichend in den frühen 2010er Jahren und hat sich seitdem rasant beschleunigt. Heute beschäftigen alle großen Vereine Datenanalysten, nutzen spezialisierte Software und treffen Entscheidungen auf Basis von Zahlen. Die Statistik hat den Fußball nicht verdrängt, aber sie hat ihn ergänzt und in vielen Bereichen verändert.

Für Sportwetten bedeutet diese Entwicklung einen fundamentalen Wandel. Früher konnten informierte Fans mit gutem Fachwissen einen Vorteil gegenüber den Buchmachern haben. Heute konkurrieren sie mit Algorithmen, die Tausende von Datenpunkten in Sekundenbruchteilen verarbeiten. Wer ohne statistische Grundlagen in diesen Markt einsteigt, ist von vornherein im Nachteil.
Das klingt entmutigend, ist es aber nicht. Die Algorithmen sind mächtig, aber sie sind nicht perfekt. Sie können Muster erkennen, die Menschen übersehen, aber sie können auch Zusammenhänge übersehen, die einem erfahrenen Beobachter offensichtlich erscheinen. Der Schlüssel liegt darin, die Stärken und Schwächen beider Ansätze zu verstehen und sie intelligent zu kombinieren.
Grundlegende statistische Konzepte
Bevor wir in die Details einsteigen, müssen einige Grundbegriffe geklärt werden. Das Konzept der Wahrscheinlichkeit bildet das Fundament jeder statistischen Analyse. Im Fußballkontext bedeutet eine Wahrscheinlichkeit von 60 Prozent für einen Heimsieg, dass bei einer großen Anzahl ähnlicher Spiele etwa sechs von zehn mit einem Heimsieg enden würden. Es bedeutet nicht, dass der Heimsieg sicher ist, und es bedeutet auch nicht, dass er wahrscheinlicher ist als alle anderen Ausgänge zusammen.
Die Varianz beschreibt, wie stark die tatsächlichen Ergebnisse um den erwarteten Wert streuen. Im Fußball ist die Varianz hoch, weil wenige Tore fallen und einzelne Ereignisse wie ein Elfmeter oder ein Platzverweis den Ausgang stark beeinflussen können. Eine Mannschaft mit einer erwarteten Torausbeute von 1,5 Toren pro Spiel wird in manchen Spielen gar kein Tor schießen und in anderen drei oder vier. Die Varianz erklärt, warum kurzfristige Ergebnisse so wenig über die tatsächliche Qualität einer Mannschaft aussagen.
Die Stichprobengröße ist ein weiteres zentrales Konzept. Je mehr Datenpunkte in eine Analyse einfließen, desto zuverlässiger sind die Ergebnisse. Ein einzelnes Spiel sagt wenig aus. Fünf Spiele geben erste Hinweise. Zwanzig Spiele erlauben einigermaßen belastbare Aussagen. Eine komplette Saison liefert ein solides Fundament. Das Problem ist, dass sich die Umstände im Fußball ständig ändern: Spieler kommen und gehen, Trainer wechseln, Taktiken werden angepasst. Die Daten von vor sechs Monaten sind möglicherweise nicht mehr relevant für die aktuelle Situation.
Die Regression zur Mitte beschreibt das statistische Phänomen, dass extreme Ergebnisse dazu tendieren, sich über Zeit dem Durchschnitt anzunähern. Eine Mannschaft, die in den ersten Spielen der Saison überdurchschnittlich viele Elfmeter zugesprochen bekommt, wird diese Quote wahrscheinlich nicht halten. Ein Stürmer, der aus jedem zweiten Schuss ein Tor macht, wird früher oder später in eine Phase geringerer Effizienz fallen. Die Regression ist keine Garantie, aber eine statistische Gesetzmäßigkeit, die bei der Bewertung von Leistungen berücksichtigt werden sollte.
Korrelation und Kausalität werden oft verwechselt, und diese Verwechslung führt zu fundamentalen Fehleinschätzungen. Wenn zwei Variablen miteinander korrelieren, bedeutet das nicht zwangsläufig, dass die eine die andere verursacht. Mannschaften mit hohem Ballbesitz gewinnen tendenziell mehr Spiele, aber das bedeutet nicht, dass Ballbesitz an sich zu Siegen führt. Die Korrelation könnte auch dadurch entstehen, dass bessere Mannschaften sowohl mehr Ballbesitz haben als auch mehr gewinnen. Diese Unterscheidung ist essenziell für die Interpretation von Daten.
Die Poisson-Verteilung und Fußballtore
Unter allen statistischen Verteilungen hat eine besondere Bedeutung für den Fußball: die Poisson-Verteilung. Sie beschreibt, wie oft ein seltenes Ereignis in einem festen Zeitraum auftritt, und eignet sich daher hervorragend für die Modellierung von Fußballtoren. Die Tatsache, dass Tore relativ selten fallen, macht die Poisson-Verteilung zum natürlichen Werkzeug für Prognosen.
Der französische Mathematiker Siméon Denis Poisson entwickelte diese Verteilung im 19. Jahrhundert, ohne an Fußball zu denken. Er wollte beschreiben, wie oft Ereignisse auftreten, die in einem großen Zeitraum vielfach möglich, aber im einzelnen Moment unwahrscheinlich sind. Diese Beschreibung passt perfekt auf Fußballtore: In 90 Minuten Spielzeit gibt es unzählige Momente, in denen ein Tor fallen könnte, aber tatsächlich fallen nur wenige.
Die praktische Anwendung funktioniert so: Wenn man annimmt, dass eine Heimmannschaft im Schnitt 1,6 Tore pro Spiel erzielt, kann man mit der Poisson-Formel berechnen, wie wahrscheinlich null Tore, ein Tor, zwei Tore und so weiter sind. Das gleiche macht man für die Auswärtsmannschaft. Durch Kombination dieser Wahrscheinlichkeiten erhält man Vorhersagen für jedes mögliche Ergebnis.
Die Poisson-Verteilung ist elegant und nützlich, aber sie hat Grenzen. Sie geht davon aus, dass Tore unabhängig voneinander fallen, also dass das erste Tor keinen Einfluss auf das zweite hat. In der Realität stimmt das nur näherungsweise. Eine Mannschaft, die in Führung geht, spielt anders als eine Mannschaft, die zurückliegt. Der Spielverlauf beeinflusst die Wahrscheinlichkeit weiterer Tore. Diese Abhängigkeiten werden von der einfachen Poisson-Modellierung nicht erfasst.
Trotz dieser Einschränkungen bleibt die Poisson-Verteilung ein fundamentales Werkzeug für Fußballprognosen. Sie bildet die Grundlage vieler KI-Modelle und erklärt, warum bestimmte Ergebnisse häufiger vorkommen als andere. Wer die Logik der Poisson-Verteilung versteht, versteht auch, warum ein 1:0 wahrscheinlicher ist als ein 4:3 und warum torlose Unentschieden häufiger auftreten, als es dem neutralen Beobachter erscheint.
Logistische Regression für Spielausgänge
Während die Poisson-Verteilung für Torprognosen verwendet wird, eignet sich die logistische Regression besser für die Vorhersage von Spielausgängen. Bei einer 1X2-Wette geht es nicht um die genaue Anzahl der Tore, sondern nur darum, welches Team gewinnt oder ob das Spiel unentschieden endet. Die logistische Regression modelliert genau solche Entscheidungssituationen.
Das Grundprinzip ist intuitiv: Man sammelt historische Daten über Spielausgänge und die Faktoren, die diese beeinflusst haben könnten. Diese Faktoren nennt man unabhängige Variablen und sie können alles umfassen, von der Tabellenposition über die Heimstärke bis zur Form der letzten Spiele. Das Modell lernt aus den Daten, welche Faktoren wie stark mit dem Spielausgang zusammenhängen.
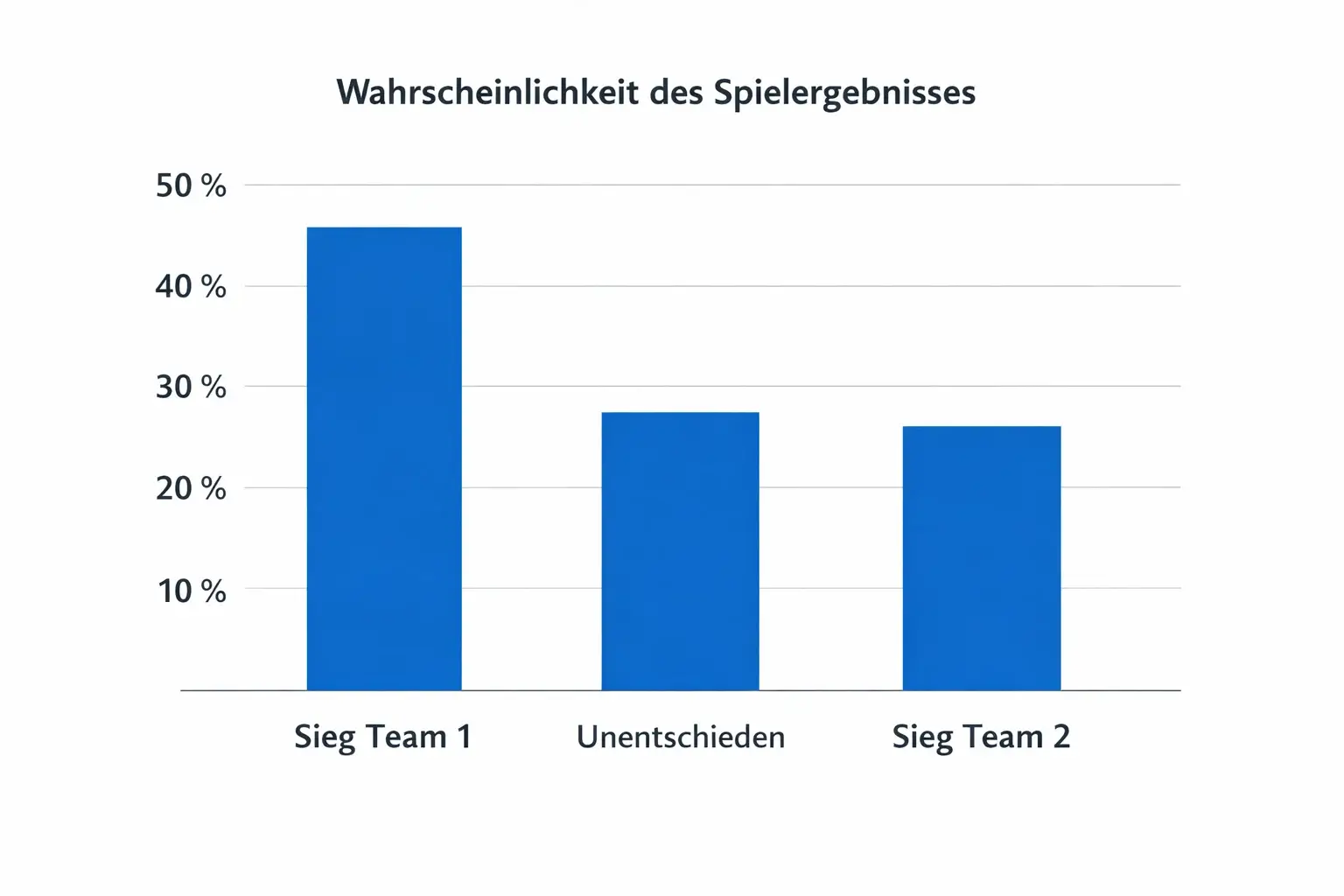
Der Output einer logistischen Regression ist eine Wahrscheinlichkeit zwischen null und eins. Basierend auf diesen Daten berechnet unsere KI auch die genaue Siegwahrscheinlichkeit für jedes Spiel. Ein Wert von 0,52 für einen Heimsieg bedeutet, dass das Modell diesem Ausgang eine Chance von 52 Prozent einräumt. Die Summe der Wahrscheinlichkeiten für alle drei möglichen Ausgänge muss stets eins ergeben. Diese Eigenschaft macht logistische Regressionen besonders nützlich für die Umrechnung in Wettquoten.
Die Stärke der logistischen Regression liegt in ihrer Interpretierbarkeit. Man kann nachvollziehen, welche Faktoren wie stark in die Prognose einfließen. Das unterscheidet sie von komplexeren Machine-Learning-Modellen, die oft als Black Box funktionieren. Der Nachteil ist, dass sie lineare Zusammenhänge bevorzugt und komplexere Wechselwirkungen zwischen Variablen nur schwer erfassen kann.
Viele moderne KI-Systeme verwenden logistische Regression als Basismodell und ergänzen sie durch aufwendigere Verfahren. Die Kombination erlaubt es, sowohl die Nachvollziehbarkeit der einfachen Modelle als auch die Präzision der komplexen Modelle zu nutzen. Für den praktischen Einsatz bedeutet das: Die grundlegende Logik ist simpel, aber die tatsächliche Implementierung kann beliebig komplex werden.
Bayesianische Ansätze im Fußball
Eine dritte statistische Richtung gewinnt zunehmend an Bedeutung: die bayesianische Statistik. Benannt nach dem englischen Pfarrer Thomas Bayes, bietet dieser Ansatz eine elegante Methode, neue Informationen in bestehende Schätzungen zu integrieren. Für dynamische Systeme wie den Fußball ist das besonders wertvoll.
Der Kern des bayesianischen Denkens ist das Konzept der Vorwahrscheinlichkeit, englisch Prior genannt. Bevor man neue Daten sammelt, hat man bereits Annahmen oder Erwartungen. Ein Spiel zwischen Bayern München und einem Aufsteiger würde die meisten Beobachter zu einer Favoritenprognose für Bayern veranlassen, auch ohne aktuelle Statistiken zu kennen. Diese Vorerwartung ist der Prior.

Wenn nun neue Daten hinzukommen, beispielsweise die Ergebnisse der letzten Spiele, aktualisiert man den Prior entsprechend. Das Ergebnis nennt man Posterior. Ein bayesianisches Modell kombiniert also das Vorwissen mit den neuen Informationen und gewichtet beides entsprechend der jeweiligen Zuverlässigkeit.
Diese Methode hat klare Vorteile für Fußballprognosen. Sie erlaubt es, mit begrenzten Datenmengen umzugehen, indem sie auf Vorwissen zurückgreift. Am Saisonanfang, wenn nur wenige Spielergebnisse vorliegen, kann ein bayesianisches Modell auf Informationen aus der Vorsaison zurückgreifen und diese graduell aktualisieren. Das führt zu stabileren Prognosen als rein datengetriebene Ansätze.
Der Nachteil liegt in der Subjektivität des Priors. Die Wahl der Vorerwartung beeinflusst das Ergebnis, und verschiedene Analysten können zu unterschiedlichen Priors kommen. In der Praxis wird versucht, diese Subjektivität durch sorgfältige Analyse historischer Daten zu minimieren, aber vollständig eliminieren lässt sie sich nicht.
Kritischer Umgang mit Statistik
Die vielleicht wichtigste Lektion im Umgang mit statistischen Analysen ist die Notwendigkeit kritischen Denkens. Zahlen wirken objektiv, aber ihre Interpretation ist es selten. Dieselben Daten können unterschiedliche Schlussfolgerungen stützen, je nachdem, wie man sie betrachtet.
Cherry-Picking ist einer der häufigsten Fehler. Dabei werden gezielt die Datenpunkte ausgewählt, die eine bestimmte Hypothese stützen, während widersprechende Daten ignoriert werden. Ein Beispiel: Eine Mannschaft hat in den letzten drei Heimspielen gegen Aufsteiger nicht verloren. Das klingt beeindruckend, bis man feststellt, dass diese drei Spiele über mehrere Saisons verteilt waren und die Mannschaft in anderen Heimspielen durchaus verloren hat. Die selektive Auswahl verzerrt das Bild.
Die Überinterpretation kleiner Stichproben ist ein verwandtes Problem. Wenn eine Mannschaft zwei Spiele hintereinander gewonnen hat, bedeutet das wenig. Der Zufall allein könnte diese Serie erklären. Erst bei längeren Serien lässt sich mit einiger Sicherheit sagen, dass die Ergebnisse kein Zufall sind. Die menschliche Tendenz, Muster auch dort zu erkennen, wo keine sind, führt regelmäßig zu Fehlschlüssen.
Die Verwechslung von Korrelation und Kausalität wurde bereits erwähnt, verdient aber Wiederholung. Sie ist einer der häufigsten und folgenreichsten Fehler in der Datenanalyse. Nur weil zwei Dinge zusammen auftreten, bedeutet das nicht, dass das eine das andere verursacht. Manchmal gibt es eine dritte Variable, die beide beeinflusst. Manchmal ist der Zusammenhang reiner Zufall. Kritisches Denken erfordert, immer nach alternativen Erklärungen zu suchen.
Schließlich gibt es das Problem der versteckten Annahmen. Jedes statistische Modell basiert auf Annahmen über die Daten und ihre Verteilung. Wenn diese Annahmen nicht erfüllt sind, können die Ergebnisse irreführend sein. Die Poisson-Verteilung nimmt an, dass Tore unabhängig fallen. Wenn diese Annahme verletzt ist, werden die Prognosen ungenauer. Die besten Analysten sind sich der Annahmen ihrer Modelle bewusst und wissen, unter welchen Umständen diese verletzt werden könnten.
Die Verbindung von Statistik und KI
Künstliche Intelligenz im Fußball ist im Kern angewandte Statistik mit erhöhter Rechenleistung. Die Algorithmen, die moderne Prognosemodelle antreiben, basieren auf den gleichen statistischen Prinzipien, die seit Jahrzehnten bekannt sind. Was sich geändert hat, ist die Fähigkeit, diese Prinzipien auf massive Datensätze anzuwenden und komplexe Muster zu erkennen.
Machine-Learning-Verfahren wie Gradient Boosting oder Random Forests sind im Grunde Erweiterungen der klassischen Regression. Sie zerlegen die Vorhersage in viele kleine Entscheidungsschritte und kombinieren die Ergebnisse zu einer Gesamtprognose. Das erlaubt ihnen, nichtlineare Zusammenhänge zu erfassen, die einfacheren Modellen entgehen.
Neuronale Netze gehen noch einen Schritt weiter und lernen die relevanten Merkmale direkt aus den Daten. Sie benötigen keine vordefinierten Features, sondern identifizieren selbst, welche Informationen für die Prognose relevant sind. Das macht sie mächtig, aber auch undurchsichtig. Die Ergebnisse eines neuronalen Netzes sind oft schwer zu interpretieren, was in einem so unberechenbaren Bereich wie dem Fußball problematisch sein kann.
Für den praktischen Anwender ist das Verständnis dieser technischen Details weniger wichtig als das Verständnis der grundlegenden Logik. Alle KI-Modelle, unabhängig von ihrer Komplexität, versuchen dasselbe: aus historischen Daten Muster zu erkennen und diese Muster auf zukünftige Ereignisse zu übertragen. Die statistischen Grundkonzepte, die in diesem Artikel beschrieben wurden, gelten für alle diese Modelle.
Die wichtigste Erkenntnis ist vielleicht diese: Statistik und KI können den Fußball nicht berechenbar machen. Sie können Wahrscheinlichkeiten schätzen, aber nicht die Zukunft vorhersagen. Ein Modell mit 70 Prozent Trefferquote liegt in drei von zehn Fällen falsch, und es gibt keine Möglichkeit vorherzusagen, welche Fälle das sein werden. Diese Unsicherheit ist kein Mangel der Methode, sondern eine fundamentale Eigenschaft des Sports. Wer das akzeptiert und seine Erwartungen entsprechend kalibriert, kann von statistischen Analysen profitieren. Wer sichere Prognosen erwartet, wird enttäuscht werden.
Die Statistik bietet Werkzeuge, um informierte Entscheidungen zu treffen, aber sie ersetzt nicht das eigene Urteilsvermögen. Sie ergänzt es, indem sie Daten strukturiert und Muster sichtbar macht, die dem bloßen Auge verborgen bleiben. Diese Kombination aus menschlicher Expertise und maschineller Analyse ist es, die langfristig den Unterschied macht.
Statistische Fallstricke in der Praxis
Die Theorie ist das eine, die Praxis das andere. Wer statistische Modelle für Fußballprognosen einsetzt, begegnet regelmäßig Situationen, in denen die Zahlen in die Irre führen können. Diese Fallstricke zu kennen ist mindestens so wichtig wie das Verständnis der Methoden selbst.

Das Overfitting-Problem tritt auf, wenn ein Modell zu gut an die historischen Daten angepasst ist. Es erklärt die Vergangenheit perfekt, versagt aber bei neuen Daten. Ein Beispiel: Ein Algorithmus lernt, dass eine bestimmte Kombination aus Wetter, Tabellenstand und Vortagesergebnissen in der Vergangenheit immer zu einem Heimsieg geführt hat. Diese Kombination trat vielleicht dreimal auf, und dreimal gewann der Gastgeber. Das Modell sieht einen klaren Zusammenhang und gewichtet diese Faktoren hoch. In Wirklichkeit war es Zufall, und bei zukünftigen Spielen wird die Vorhersage falsch sein.
Survivorship Bias ist ein subtileres Problem. Dabei werden nur die erfolgreichen Fälle analysiert, während die gescheiterten außer Acht bleiben. Wenn jemand behauptet, sein System habe in den letzten sechs Monaten 70 Prozent Trefferquote erreicht, stellt sich die Frage: Wie viele Systeme wurden in dieser Zeit ausprobiert? Wenn zehn verschiedene Ansätze getestet wurden und neun davon verworfen wurden, ist das überlebende System möglicherweise einfach das, das zufällig Glück hatte.
Die Vernachlässigung von Kontextfaktoren ist ein weiterer häufiger Fehler. Statistische Modelle erfassen, was gemessen wird, aber nicht alles ist messbar. Die Motivation einer Mannschaft vor einem Derby, die Nervosität eines jungen Spielers in seinem ersten großen Spiel, die Anspannung eines Trainers unter Druck, all das beeinflusst den Spielausgang, taucht aber in keiner Statistik auf. Wer sich ausschließlich auf Zahlen verlässt, übersieht diese Faktoren systematisch.
Die Zeitverzögerung bei Daten ist ein praktisches Problem, das oft unterschätzt wird. Statistiken basieren auf vergangenen Spielen, aber der Fußball ist dynamisch. Ein Spieler, der vor einem Monat eine Topform hatte, kann heute müde oder verletzt sein. Ein Taktikwechsel unter einem neuen Trainer braucht Zeit, um sich in den Statistiken niederzuschlagen. Die aktuellsten Daten sind oft mehrere Wochen alt, und in dieser Zeit kann sich viel verändert haben.
Datenquellen und ihre Qualität
Nicht alle Daten sind gleich wertvoll, und die Qualität der Eingabedaten bestimmt die Qualität der Prognosen. Im Bereich der Fußballstatistik gibt es erhebliche Unterschiede zwischen verschiedenen Anbietern und Datentypen.
Ergebnisdaten sind am zuverlässigsten. Ein 2:1 ist ein 2:1, daran gibt es nichts zu interpretieren. Diese Basisdaten bilden das Fundament jeder Analyse und sind in der Regel fehlerfrei verfügbar. Das Problem ist, dass Ergebnisse allein nur begrenzte Aussagekraft haben, wie bereits diskutiert wurde.
Ereignisdaten wie Schüsse, Ecken oder Fouls erfordern bereits eine gewisse Interpretation. Wann ist ein Schuss ein Schuss? Zählt ein abgeblockter Ball? Die Definitionen variieren zwischen Anbietern, was die Vergleichbarkeit erschwert. Hinzu kommen menschliche Fehler bei der Erfassung, die nie vollständig auszuschließen sind.
Tracking-Daten, die präzise Positionsinformationen aller Spieler erfassen, sind am detailreichsten, aber auch am komplexesten. Sie erfordern spezialisierte Technologie und sind nicht für alle Ligen verfügbar. Die großen europäischen Top-Ligen bieten umfassende Tracking-Daten, aber sobald man sich in niedrigere Spielklassen oder exotischere Wettbewerbe begibt, wird die Datenlage dünn.
Die Konsequenz für die Praxis ist klar: Die besten Prognosen entstehen dort, wo die Datenqualität am höchsten ist. Für die Bundesliga oder die Premier League stehen hervorragende Daten zur Verfügung. Für eine vierte Liga in einem osteuropäischen Land sieht das anders aus. Wer auf solche Ligen wettet, muss mit höherer Unsicherheit rechnen und sollte seine Erwartungen entsprechend anpassen.
Von den Zahlen zur Wettentscheidung
Statistik ist ein Werkzeug, kein Selbstzweck. Am Ende steht die Frage, wie man die gewonnenen Erkenntnisse in konkrete Wettentscheidungen übersetzt. Der Übergang von der Analyse zur Aktion ist der kritische Schritt, an dem viele scheitern.
Der erste Grundsatz lautet: Niemals auf Basis eines einzelnen Faktors wetten. Eine Statistik, die einen Vorteil suggeriert, ist ein Hinweis, kein Beweis. Die Kombination mehrerer unabhängiger Indikatoren erhöht die Zuverlässigkeit der Prognose. Wenn sowohl die Form, als auch die historischen Direktvergleiche, als auch die aktuelle Tabellensituation in dieselbe Richtung weisen, ist das aussagekräftiger als ein einzelner Datenpunkt.
Der zweite Grundsatz betrifft das Verhältnis von Prognose und Quote. Eine statistische Vorhersage ist nur dann wertvoll, wenn sie sich von der Marktmeinung unterscheidet. Wenn das eigene Modell eine Heimsiegwahrscheinlichkeit von 60 Prozent berechnet und der Markt dieselbe Wahrscheinlichkeit impliziert, gibt es keinen Vorteil. Der Mehrwert entsteht erst durch Diskrepanzen, also Situationen, in denen das eigene Modell zu anderen Schlüssen kommt als der Markt.
Der dritte Grundsatz ist die Akzeptanz von Verlusten. Selbst das beste statistische Modell liegt regelmäßig falsch. Das ist keine Schwäche, sondern eine unvermeidliche Konsequenz der Unvorhersehbarkeit des Sports. Die richtige Reaktion auf einen Verlust ist nicht die Suche nach Fehlern im Modell, zumindest nicht automatisch. Manchmal liegt das Modell richtig und das Ergebnis ist trotzdem anders. Das gehört dazu.
Die langfristige Perspektive ist entscheidend. Statistische Vorteile zeigen sich nicht in einzelnen Wetten, sondern in Serien von hunderten oder tausenden Wetten. Wer nach zehn verlorenen Wetten sein System über Bord wirft, hat möglicherweise genau dann aufgegeben, als die Varianz sich zu drehen begann. Geduld und Disziplin sind keine statistischen Konzepte, aber sie sind unverzichtbar für jeden, der mit Statistik arbeitet.
Der Wert des Verstehens
Am Ende dieses Artikels steht keine Formel für garantierten Erfolg. Die gibt es nicht und wird es nie geben. Was bleibt, ist ein Verständnis für die Logik, nach der datenbasierte Prognosen funktionieren. Dieses Verständnis ist wertvoll, auch wenn es keine einfachen Antworten liefert.
Wer die statistischen Grundlagen kennt, kann die Outputs von KI-Modellen besser einordnen. Eine Vorhersage mit 55 Prozent Wahrscheinlichkeit für den Heimsieg bedeutet etwas anderes als eine mit 80 Prozent. Die Konfidenz der Prognose, also wie sicher sich das Modell ist, ist mindestens so wichtig wie die Prognose selbst.

Wer die Fallstricke kennt, vermeidet kostspielige Fehler. Die Überinterpretation kleiner Stichproben, das Cherry-Picking von Daten, die Verwechslung von Korrelation und Kausalität, all das sind Fehler, die mit statistischem Grundwissen vermieden werden können. Nicht jeder dieser Fehler ist offensichtlich, und selbst erfahrene Analysten fallen manchmal darauf herein.
Wer die Grenzen kennt, bewahrt sich eine gesunde Skepsis. Statistik ist mächtig, aber sie ist nicht allmächtig. Fußball enthält ein Element der Unvorhersehbarkeit, das keine Analyse vollständig erfassen kann. Diese Unvorhersehbarkeit ist kein Bug, sondern ein Feature, sie macht den Sport erst interessant.
Die Verbindung von statistischem Wissen und Fußballverständnis ist das Ideal. Die Zahlen liefern das Fundament, die Erfahrung liefert den Kontext. Wer beides kombiniert, hat die besten Chancen auf langfristigen Erfolg. Nicht weil er immer richtig liegt, sondern weil er systematisch bessere Entscheidungen trifft als jemand, der nur auf sein Bauchgefühl hört oder nur auf die Zahlen starrt. Das ist der Wert des Verstehens, und er ist nicht zu unterschätzen.